Apache Impala는 대규모 데이터 집합에 대한 실시간 쿼리 및 분석을 수행하기 위해 설계된 오픈 소스 분산 쿼리 엔진입니다.
Impala는 Apache Hadoop의 일부인 Apache Hadoop Distributed File System (HDFS)와 호환되며, 대규모 클러스터에서 매우 빠른 응답 시간을 제공하면서 SQL 기반의 쿼리 언어를 사용하여 데이터를 탐색할 수 있습니다.
Impala는 기존의 배치 처리 방식과 달리 데이터를 인메모리로 처리하여 실시간으로 응답할 수 있습니다.
이는 많은 양의 데이터를 처리하는 데 필수적인 요소입니다. Impala는 Hadoop의 생태계와도 긴밀하게 통합되어 있으며, Apache Hive 메타스토어를 공유하여 테이블 및 스키마 메타데이터를 재사용할 수 있습니다.
Impala를 사용하면 데이터 분석가와 데이터 엔지니어는 SQL 기반의 쿼리를 사용하여 데이터를 탐색하고 복잡한 분석을 수행할 수 있습니다.
이를 통해 대화형 분석 및 반복적인 작업에 소요되는 시간을 크게 줄일 수 있습니다.
Impala는 다양한 데이터 형식을 지원하며, 일반적인 BI 도구와도 연동하여 데이터 시각화 및 대시보드 작성 등을 수행할 수 있습니다.
또한 Impala는 확장성이 뛰어나며, 수천 대의 노드로 구성된 대규모 클러스터에서 작동할 수 있습니다.
이러한 클러스터는 데이터를 분산하여 처리하므로 매우 높은 성능과 처리량을 제공할 수 있습니다.
Impala는 Hadoop 클러스터와 함께 사용할 수 있으며, 기존의 하둡 데이터 처리 작업과 통합하여 사용할 수 있습니다.
요약하자면, Apache Impala는 대규모 데이터 집합에 대한 실시간 SQL 기반 쿼리 및 분석을 제공하는 분산 쿼리 엔진입니다.
Impala를 사용하면 대용량 데이터를 실시간으로 탐색하고 분석할 수 있으며, Hadoop과의 긴밀한 통합과 확장성이 특징입니다.
by charGPT
'TiP™Log' 카테고리의 다른 글
| ipad 블루투스 키보드 한영 전환 버그 & ipad 매직마우스 1세대 연결 불편함 (1) | 2023.06.08 |
|---|---|
| 지식 그래프 (Knowledge Graph) (0) | 2023.05.12 |
| Apache Kafka와 Spark 그리고 Nifi를 이용해서 데이터 pipeline을 구현 구성 방안 , Object Storage OpenSource 설명 (0) | 2023.05.12 |
| Nifi 설명 (0) | 2023.05.12 |
| Hive 설명 (0) | 2023.05.12 |
| Kafka 설명 (0) | 2023.05.12 |
| SPARK 설명 (1) | 2023.05.12 |
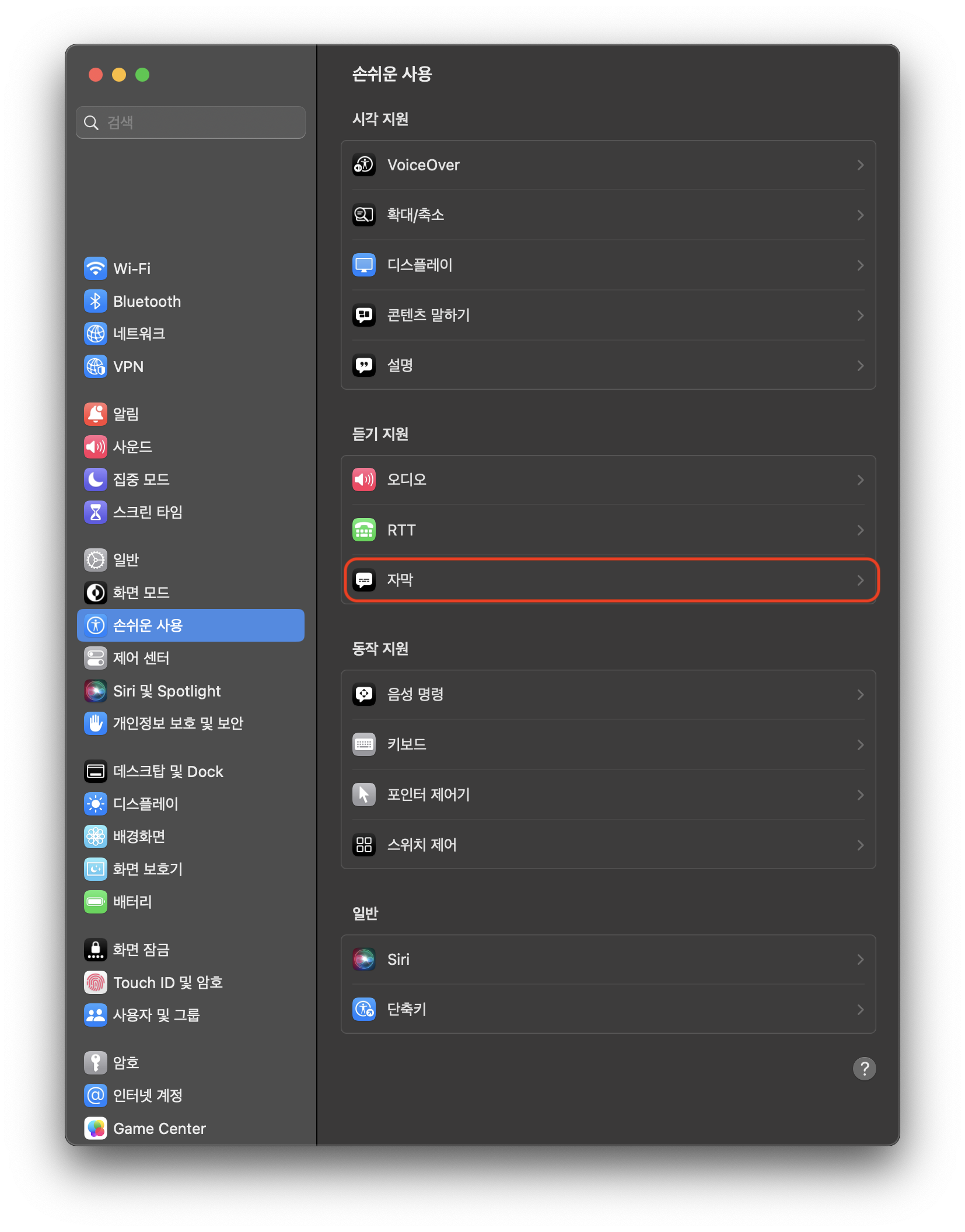
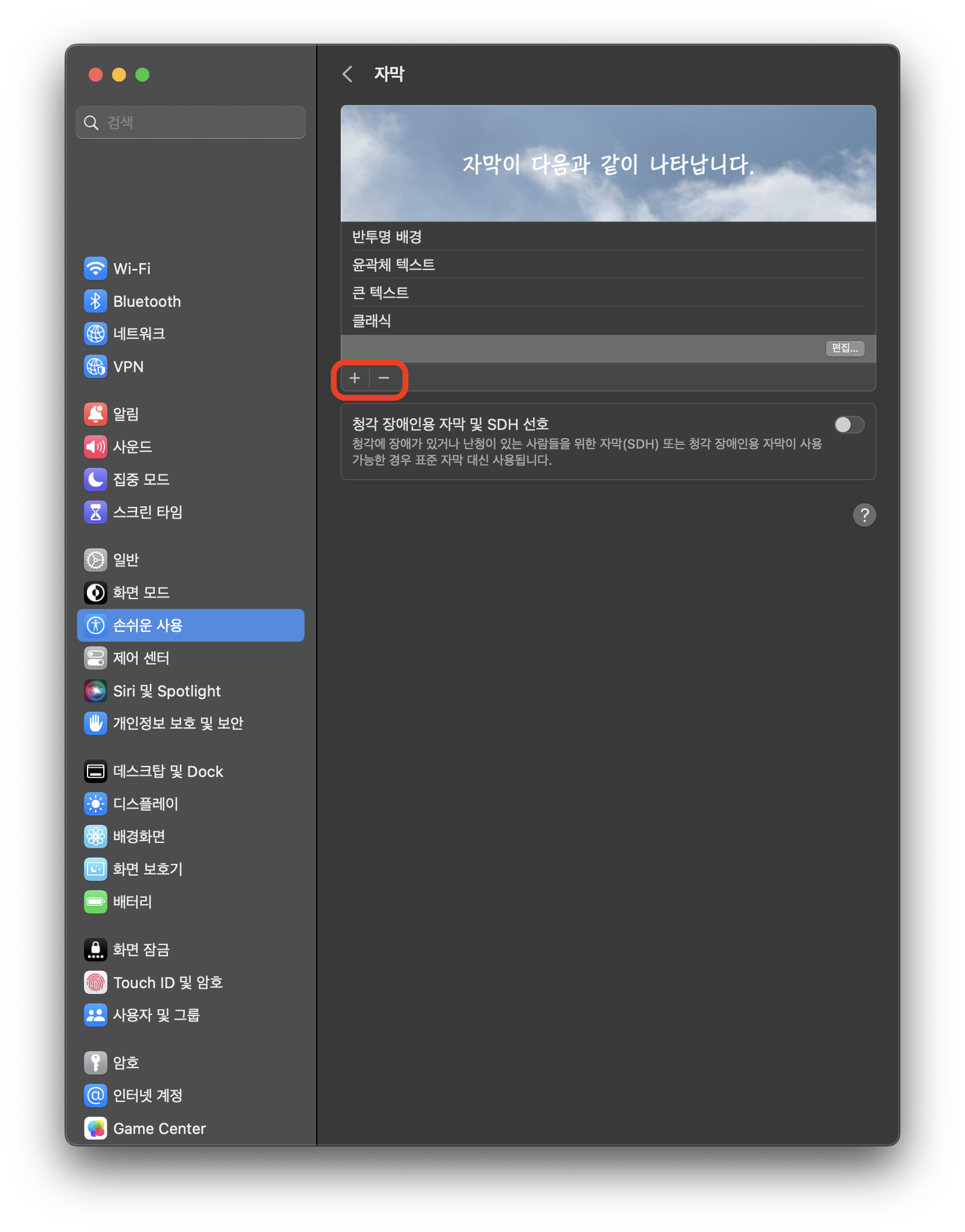
| [Mac] 애플TV 자막 설정하기 (0) | 2023.05.10 |
WRITTEN BY
- bca (brainchaos)
언저리 - 블로그 = f UN + b LOG #BigData, #GrapDB, #Ani, #Game, #Movie, #Camping, 보드, 술먹고 떠들기, 멍때리기, 화장실에서 책읽기, 키스, 귀차니즘, 운동싫어, 버럭질 최고, 주경야독, May The Force be With You